E-SMOTE: Entropy Based Minority Oversampling for Heart Failure and AIDS Clinical Trails Analysis
Authors: Anbu Valluvan, Sainath Veerla
Published in: 2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC)
Date of Conference: 02-04 July 2024
Date Added to IEEE Xplore: 26 August 2024
DOI: 10.1109/COMPSAC61105.2024.00291
Publisher: IEEE
Conference Location: Osaka, Japan
Abstract
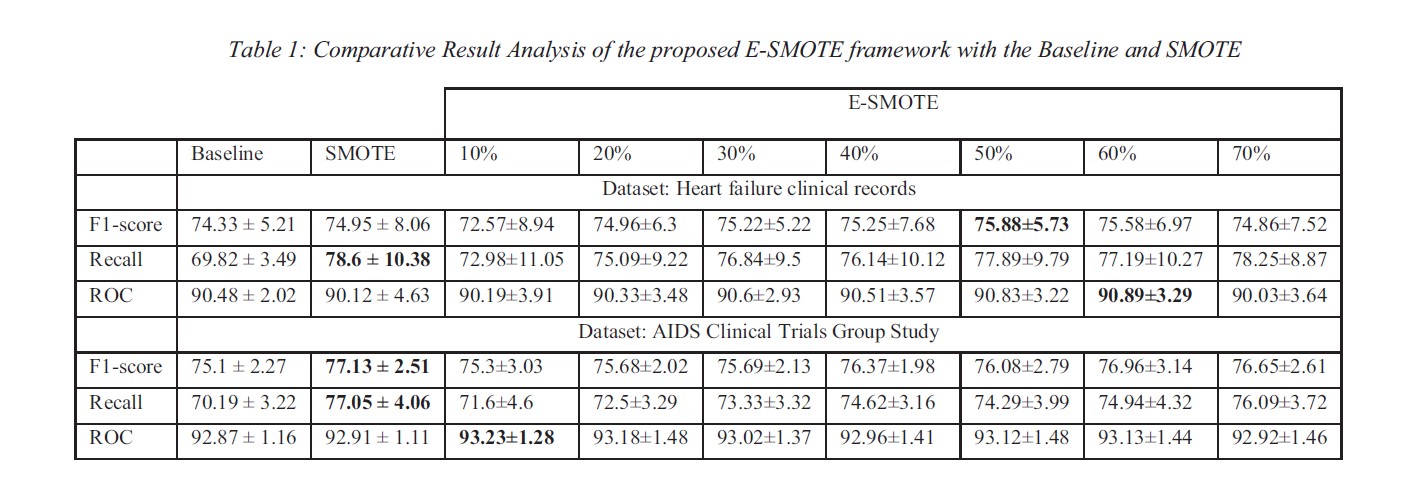
Machine Learning (ML) algorithms often exhibit reduced performance in the presence of class imbalance, leading to biased results favoring the majority class in a dataset. This imbalance can be addressed through various sampling techniques, including oversampling of the minority class, undersampling of the majority class, or a combination of both. However, these techniques utilize the entire set of samples of datasets. In this paper, we introduce E-SMOTE, an Entropy-based Synthetic Minority Oversampling Technique (SMOTE), which extends the traditional SMOTE method. E-SMOTE is a novel oversampling technique designed to utilize a subset of the dataset from the minority class for the oversampling process. We employ entropy as a guiding metric to identify influential minority class instances located near decision boundaries. By generating additional instances near these boundaries within a binary classification system, E-SMOTE strengthens the decision boundary during the ML classifier training process. We conducted experiments on two datasets, Heart Failure Records and AIDS Clinical Trail Records, to demonstrate the effectiveness of E-SMOTE compared to traditional SMOTE. Our experimental results illustrate that E-SMOTE outperforms baseline classifier for both Heart Failure and AIDS clinical trial datasets. Additionally, it provides reasonable and comparable performance using a subset of the datasets compared to SMOTE oversampling technique using the entire dataset.